
A new Google video generation model called Gemini Omni leaked through the Gemini mobile app days before Google I/O 2026.
X user Thomas16937378 discovered a UI string in Gemini’s video generation tab on May 2 reading “Start with an idea or try a template. Powered by Omni.” TestingCatalog quickly reported the finding which spread across the artificial intelligence community within hours.
The leak suggests Google is developing a unified model capable of handling text, images, and video generation. Gemini Omni appeared right next to Toucan, the internal codename for Google’s current Veo 3.1-powered video pathway. However, early feedback indicates Omni may already outperform Veo in several areas including prompt adherence and voice generation.
Reddit users spotted the new model inside the Gemini mobile app with capabilities for remixing clips and editing videos. Furthermore, the model can generate cinematic scenes with synchronized audio directly through chat prompts. Early demo clips shared online showcase improved realistic movement, facial expressions, and camera angle transitions.
One user shared their interactions with Gemini after the ramp-up as:
Comment
by
u/Zacatac_391 from discussion
in
GeminiAI
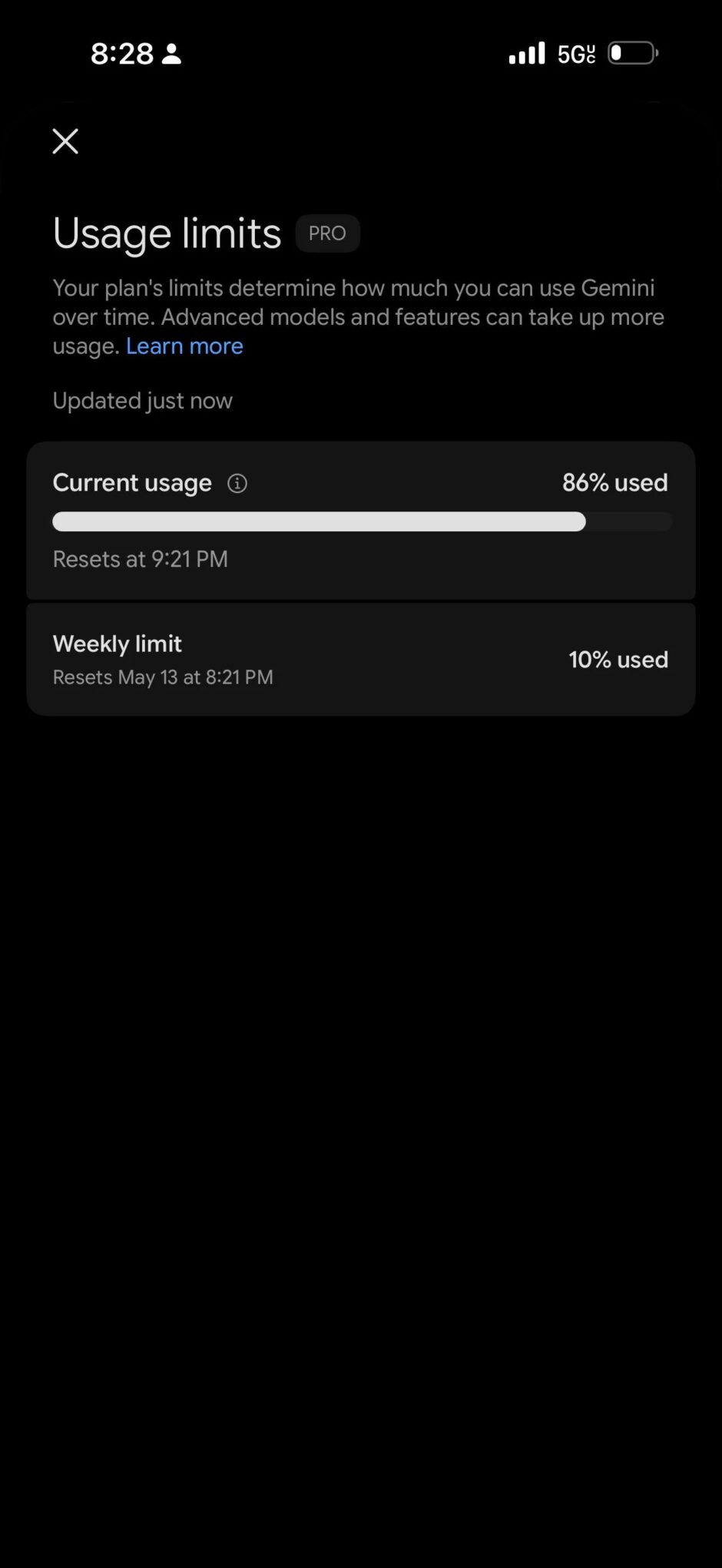
The original poster on r/GeminiAI also shared a screenshot of the usage limits:
Google I/O 2026 opens May 19-20 at Shoreline Amphitheatre where Gemini and artificial intelligence updates are confirmed. The timing of the leak appearing exactly two weeks before the event follows Google’s established pattern. Consequently, industry observers expect Omni to receive significant stage time during the keynote presentation.
Additional leaks reported by Pankaj Kumar suggest Google is testing new Gemini versions 3.2 and 3.5 focused on speed. Meanwhile, a long-term memory feature codenamed Teamfood and a visual model called Spark Robin are also under development.
On the other hand, Thomas16937378 has since deleted his X account.

















