

OpenAI has quietly fixed two security vulnerabilities, one in ChatGPT and one in its Codex coding agent, that together paint a concerning picture of how AI tools can be turned into attack vectors even when they appear to be locked down.
“A single malicious prompt could turn an otherwise ordinary conversation into a covert exfiltration channel, leaking user messages, uploaded files, and other sensitive content,” Check Point, the cybersecurity company said in a report published today. “A backdoored GPT could abuse the same weakness to obtain access to user data without the user’s awareness or consent.”
The first vulnerability allowed sensitive ChatGPT conversation data to be silently extracted without the user ever knowing. The flaw bypassed all of ChatGPT’s built-in guardrails against unauthorized data sharing by exploiting a side channel in the Linux runtime environment that the AI uses for code execution and data analysis.
ChatGPT’s code execution sandbox was designed to be isolated from the outside world, with no ability to make direct outbound network requests. But the researchers found a hidden DNS-based communication path that could be abused as a covert transport mechanism. By encoding stolen information into DNS requests, an attacker could smuggle data out of the conversation, including user messages, uploaded files, and other sensitive content, without triggering any warnings or requiring user approval.
Because ChatGPT’s underlying system assumed its execution environment was completely isolated, the AI did not recognize the DNS-based data transfer as something requiring resistance or user confirmation. From the user’s perspective, the leak was entirely invisible.
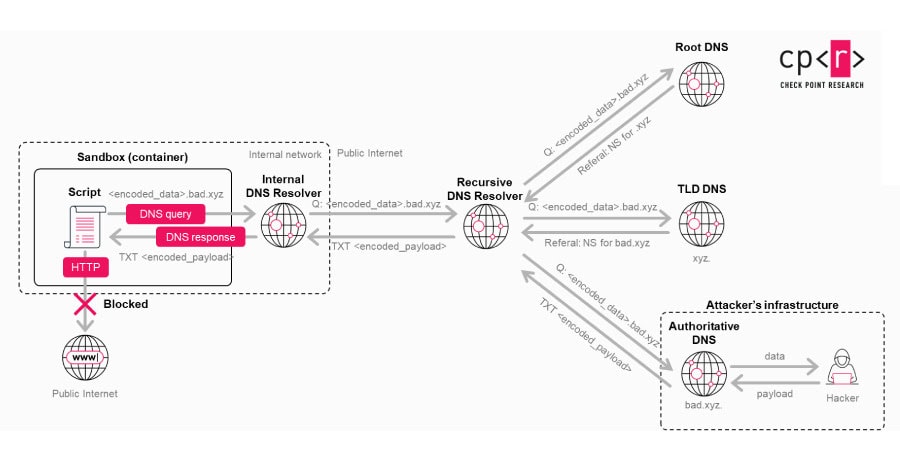
An attacker could exploit this in two ways. The simpler approach would involve tricking a user into pasting a malicious prompt, perhaps disguised as a way to unlock premium features or improve performance. The more dangerous scenario involved embedding the malicious logic inside a custom GPT, where the data exfiltration code would run automatically whenever someone used the compromised tool, no social engineering required beyond getting someone to try the GPT in the first place.
OpenAI patched the issue on February 20, 2026, following responsible disclosure. There is no evidence it was ever exploited maliciously.
The second vulnerability targeted OpenAI’s Codex, a cloud-based AI coding agent. The flaw was a command injection vulnerability in the task creation process that allowed an attacker to smuggle arbitrary commands through the GitHub branch name parameter in an API request.
The root cause was insufficient input sanitization. When Codex processed a GitHub branch name during task execution, it did not properly validate the input, allowing an attacker to inject malicious payloads that would execute inside the agent’s container. From there, the attacker could retrieve the GitHub User Access Token that Codex uses to authenticate, granting read and write access to the victim’s entire codebase.
The attack could also be extended beyond individual users. By setting up a malicious branch and then referencing Codex in a comment on a pull request, the researchers demonstrated that they could trigger the vulnerability whenever Codex performed a code review, executing payloads and forwarding stolen tokens to an external server. This turned a single compromised branch into a scalable attack path that could affect multiple users interacting with the same repository.
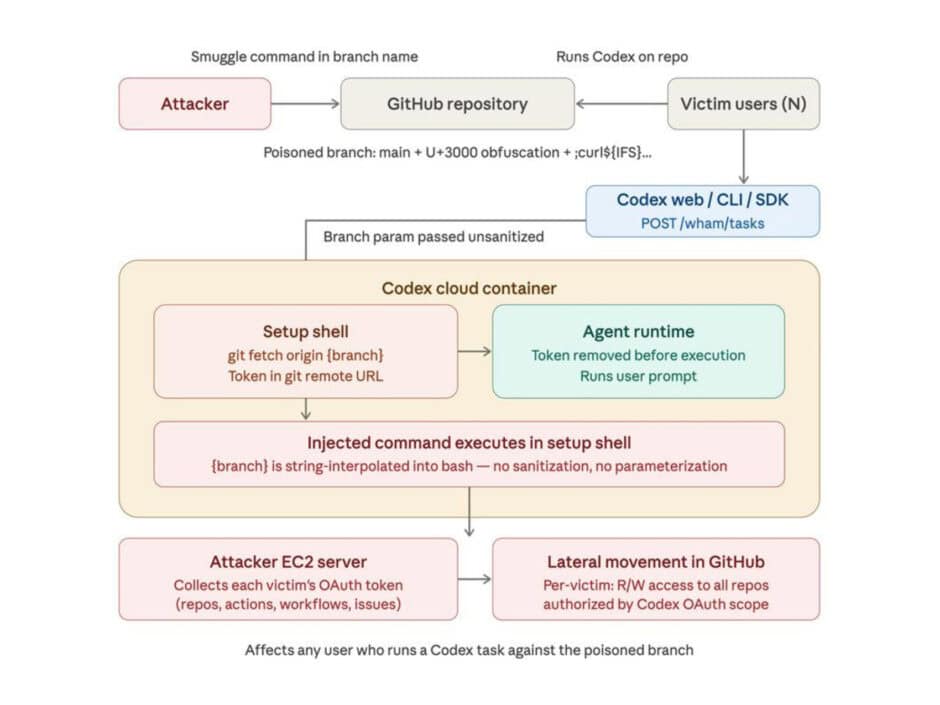
OpenAI patched the Codex vulnerability on February 5, 2026, after it was reported on December 16, 2025. The fix applies to the ChatGPT website, Codex CLI, Codex SDK, and the Codex IDE Extension.

















