
We know that machine learning exists to create programs that can learn to do something, be it distinguishing between simple cat and dog images or recommend the perfect shows to you on Netflix. There are primarily two ways in which machine learning can be performed: supervised and unsupervised learning. In case you need a primer, you can check out our Deep Dive on those learning models here.
Optimization is the cornerstone of every machine learning algorithm. After all, in order to arrive at the most accurate results possible, every algorithm must rely on some optimization technique to minimize error and increase accuracy. In this Deep Dive, we shall look at one of the most popular and simplest optimization algorithms out there – gradient descent.
What is Gradient Descent?
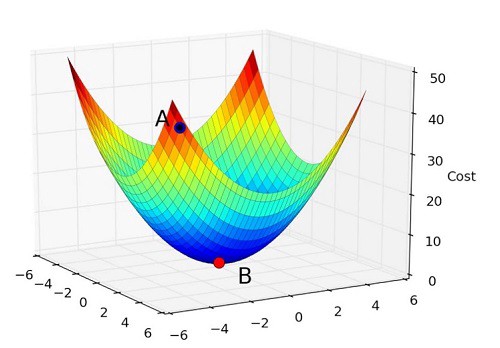
As an optimization algorithm, gradient descent attempts to find values for the parameters of a function such that they minimize the cost function. So, if we assume there is a function f, with two parameters x and y, an optimization algorithm like gradient descent wants to find the optimal values of x and y for which the value of the function becomes a minimum.
In order to visualize this in action, think of a bowl. Notice how it’s curved and has a base that represents the lowest point. Any random position on the surface of this bowl is the cost of the current values of the parameters. Meanwhile, the base of the bowl is the cost of the best set of parameters, since these parameters give us the lowest point possible on the bowl.
The goal is to continue to try different values for the parameters, evaluate their cost and select new parameters that have a slightly better (lower) cost.
Repeating this process enough times will lead to the bottom of the bowl and you will know the values of the parameters that result in the minimum cost.
The Gradient Descent Procedure
You start off with a set of initial values for all of your parameters. While typically initialize with 0.0, you could also start with very small random values.
The cost of the parameters is then evaluated by plugging them into the associated function and calculating the cost, which would look something like this:
parameter = 0.0
cost = function (parameter)
The derivative of the cost is calculated. The derivative refers to the slope of the function at a given point. We need to know the slope so that we know the direction (sign) to move the parameter values in order to get a lower cost on the next iteration. This is what it looks like, with the derivative termed delta:
delta = derivative(cost)
Now that we have the derivative, we can use it to update the value of the parameter. We can also specify a learning rate parameter (alpha) here to adjust the rate at which the parameters change on each update:
coefficient = coefficient – (alpha * delta)
This process is repeated until the cost is 0.0 (or close enough to it). And that is about it. This is why gradient descent is known as such a simple optimization algorithm.
Tips for implementing gradient descent
For each algorithm, there is always a set of best practices and tricks you can use to get the most out of it. The same holds true for gradient descent. Here are three tips you might want to consider the next time you find yourself working with it:
- Learning Rate: The learning rate is supposed to be a small value, like 0.1, 0.002, and 0.0001. Try many such small values and see which one works best for your particular application.
- Plot Cost vs Time: Collect and plot the cost values produced by the algorithm in each iteration. You can tell that a gradient descent algorithm is performing well if there is a decrease in cost at each iteration. If there is no decrease, you might want to look at your dataset or adjust the learning rate.
- Rescale your inputs: The gradient descent algorithm gets to a minimum value faster if the shape of the cost function is not skewed or distorted. It needs to have a nice, regular shape. You can typically achieve this by re-scaling your inputs to fall within the same range, like [0,1] or [-10,10].


















