

Google introduced DiffusionGemma on June 10, an experimental open model that generates text up to 4x faster than traditional autoregressive language models. Released under an Apache 2.0 license, the 26B Mixture of Experts model represents a fundamental shift in how AI generates text.
Unlike conventional language models that generate one token at a time, DiffusionGemma drafts entire blocks of 256 tokens simultaneously. The model starts with a canvas of random placeholder tokens and iteratively refines them through multiple passes, locking in correct tokens while using them as context clues for remaining output.
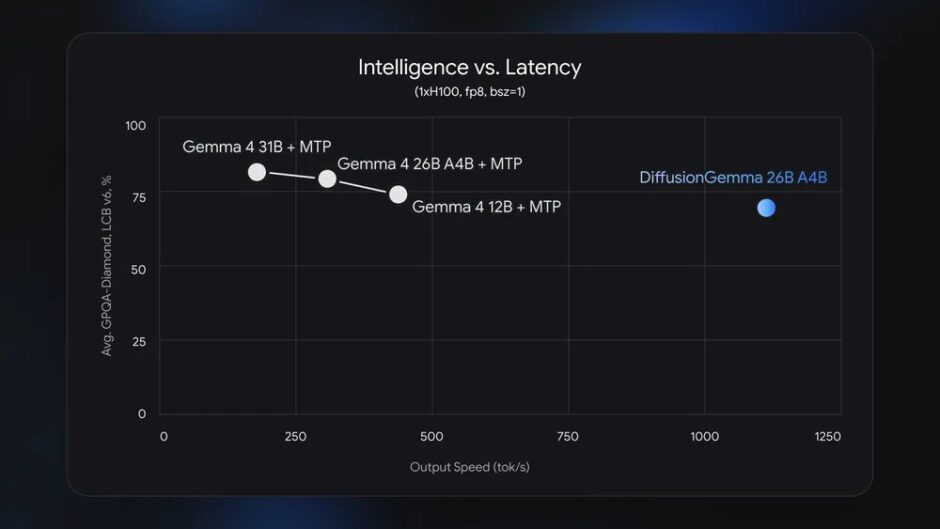
This parallel approach yields remarkable speed: 1,000 tokens per second on a single NVIDIA H100 GPU and 700 tokens per second on NVIDIA GeForce RTX 5090. The model activates only 3.8B of its 26B parameters during inference, fitting within 18GB VRAM on high-end consumer GPUs when quantized.
Google designed DiffusionGemma for local and interactive workflows where sequential token processing creates latency bottlenecks. Use cases include in-line code editing, rapid iteration, and generating non-linear text structures. The bi-directional attention mechanism allows every token to attend to all others, making the model particularly effective at tasks like code infilling and mathematical formatting where future context informs earlier decisions.
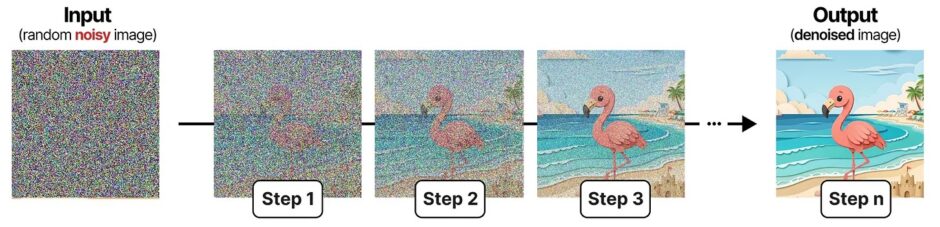
The model includes intelligent self-correction, iteratively refining entire text blocks to catch and fix errors in real-time. Developers fine-tuned DiffusionGemma to solve Sudoku, a task autoregressive models struggle with because each token depends on future tokens.

DiffusionGemma prioritizes speed over quality. Google recommends standard Gemma 4 for applications demanding maximum output quality. The speed advantage is strongest on single accelerators at low-to-medium batch sizes. In high-concurrency cloud serving, autoregressive models deployed at scale can efficiently saturate compute, making DiffusionGemma’s parallel decoding less advantageous.
Developers can access DiffusionGemma on Hugging Face, vLLM, MLX, and NVIDIA platforms. Full fine-tuning support includes tools like Unsloth, NVIDIA NeMo, and Hackable Diffusion. Google collaborated with NVIDIA to optimize performance across consumer GPUs and enterprise hardware including DGX and RTX PRO systems.

















