

What do speech recognizers, automatic translators, and AlphaGo have in common? They are all based on neural networks. If you have ever heard of “deep learning”, you have also heard of neural networks. In fact, while it is tempting to believe that neural nets are a modern technological phenomenon, they have been around the artificial intelligence block for more than 70 years now.
First introduced by University of Chicago researchers Warren McCullough and Walter Pitts in 1944, neural nets have remained prominent areas of research in both neuroscience and computer science.
While they dipped into obscurity over the years, neural nets have come rushing back into the mainstream over the past decade, courtesy of massive improvements in computing power and the discovery of smart ways of implementing these algorithms. In this Deep Dive, we shall explore the world of neural networks and deep learning.
What is a neural network, and how does it work?
You might have seen images of neural networks all around you. A bunch of circles all connected together by these straight lines. This complicated depiction of interconnectedness is no coincidence; after all, a neural net is inspired by none other than the human brain itself.
Neural nets are essentially machine learning algorithms. This means that they enable a program to learn something by analyzing labelled or unlabeled training samples. While conventional machine learning algorithms come up with neat statistical ways of predicting some output, be it the Naïve Bayes Theorem or Decision Trees, neural nets try to recognize patterns and learn a task by emulating our brains.
Comprising of thousands or even millions of simple processing nodes (neurons) that are often deeply interconnected, neural nets are organized into distinct layers. There is typically one input layer, followed by some number of hidden layers, and a final output layer. Any one node might be connected to several nodes in the layer behind it, from which it receives data, and several nodes in the layer in front of it, to which it sends data.
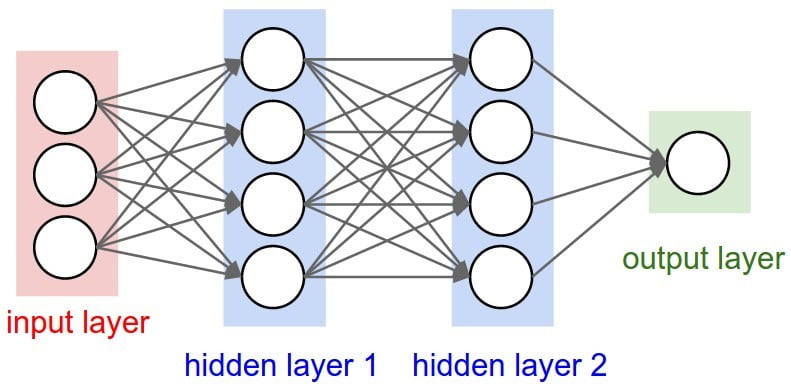
To each of its incoming connections, a node will assign a number known as a “weight.” When the network is active, the node receives a different data item over each of its connections and multiplies it by the associated weight. It then adds the resulting products together, producing a single number. If that number is below a threshold value, the node passes no data to the next layer. If the number exceeds the threshold value, the node “fires,” which in today’s neural nets generally means sending its result — the sum of the weighted inputs — along all its outgoing connections.
At the onset of the training phase, a neural net’s weights and thresholds are initialized with random values. Training data is fed to the input layer, and passed through successive layers, getting processed at each node, until it arrives at the output layer. During training, the wights and thresholds are continually adjusted until optimal results are achieved.
Popular types of neural networks
- Feed Forward
An artificial neural network in which the nodes do not ever form a cycle. In this neural network, all the perceptrons (nodes in a neural net) are arranged in layers where the input layer takes in input, and the output layer generates output, with any number of hidden layers in between. The nodes are fully connected, and there are no back-loops in this network. Common applications include data compression, pattern recognition, and computer vision.
- Recurrent Neural Net (RNN)
A variation of feed forward neural nets. Each of the neurons in the hidden layers receives an input with a specific delay in time. We use this type of neural network where we need to access previous information in current iterations. For example, when we are trying to predict the next word in a sentence, we need to know the previously used words first. Applications include speech recognition, music composition, and machine translation.
- Long/Short Term Memory (LSTM)
Comprise of a memory cell. These neural nets can process data with memory gaps. Better than RNNs in the sense that they can “remember” data from a long time ago and are better able to process a larger number of relevant data. Applications include speech and writing recognition.
- Convolutional Neural Net (CNN)
Neural nets that are primarily used for the classification and clustering of images, and for object recognition. Convolutional neural sets successfully capture the Spatial and temporal dependencies in an image through the application of relevant filters. The architecture performs a better fitting to the image dataset due to the reduction in the number of parameters involved and reusability of weights. Applications include image recognition and video analysis.

















