

OpenAI released GPT-5.5 on Thursday, its latest artificial intelligence model that excels at coding, computer use and scientific research capabilities. The launch comes just six weeks after the company debuted GPT-5.4.
GPT-5.5 Core Capabilities and Performance
GPT-5.5 handles multi-step work with less human guidance. The model can plan, use tools and verify its own output without requiring users to manage every step. OpenAI President Greg Brockman said what is really special about this model is how much more it can do with less guidance.
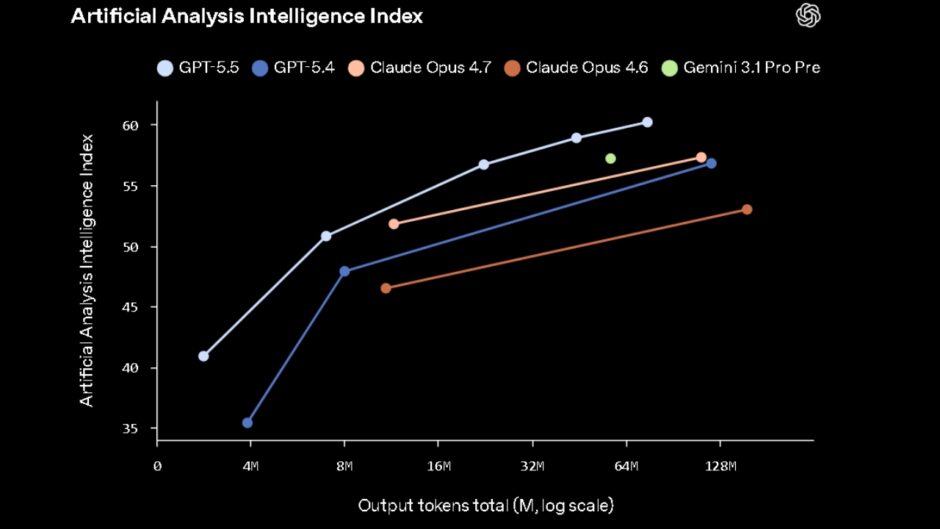
GPT-5.5 achieved an 82.7% score on Terminal-Bench 2.0, which measures AI models’ ability to use command line tools. Claude Opus 4.7 scored 69.4% on the same benchmark. On Artificial Analysis’s Intelligence Index, GPT-5.5 scored 60, three points ahead of Claude Opus 4.7 and Gemini 3.1 Pro Preview which both scored 57.
However, not every benchmark favors GPT-5.5. On SWE-Bench Pro, Claude Opus 4.7 wins at 64.3% versus 58.6%. On multilingual Q&A, GPT-5.5 scored 83.2% behind Opus 4.7 at 91.5% and Gemini 3.1 Pro at 92.6%.
Pricing and Architecture Changes
The standard edition costs $5 per million input tokens and $30 per million output tokens. This represents a doubling from GPT-5.4 which was priced at $2.50 per million input and $15 per million output. GPT-5.5 Pro costs $30 per million input tokens and $180 per million output tokens.
GPT-5.5 represents the first fully retrained base model since GPT-4.5. The architecture, pretraining corpus and agent-oriented objectives have all been reworked. The model ships with a 1 million token context window.
As OpenAI puts it:
GPT‑5.5 reaches state-of-the-art performance across multiple benchmarks that reflect this kind of work. On GDPval, which tests agents’ abilities to produce well-specified knowledge work across 44 occupations, GPT‑5.5 scores 84.9%. On OSWorld-Verified, which measures whether a model can operate real computer environments on its own, it reaches 78.7%. And on Tau2-bench Telecom, which tests complex customer-service workflows, it reaches 98.0% without prompt tuning. GPT‑5.5 also performs strongly across other knowledge work benchmarks: 60.0% on FinanceAgent, 88.5% on internal investment-banking modeling tasks, and 54.1% on OfficeQA Pro.
Rollout and Competitive Positioning
GPT-5.5 rolled out to Plus, Pro, Business and Enterprise users in ChatGPT and Codex starting Thursday. The company revealed it has 4 million active Codex users and 9 million paying business users. ChatGPT has more than 900 million weekly active users and over 50 million subscribers.
The new model release represents an extremely fast turnaround that underscores how fiercely frontier AI labs are competing for enterprise customers. OpenAI had released GPT-5.4 only six weeks ago.

















